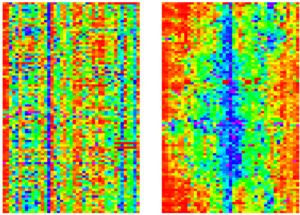
Visual DB (Semeion©)
Dato un insieme di dati disposti in uno spazio “piano” composto da righe (chiamate record) per colonne (le variabili), disposte casualmente. L’obiettivo dell’algoritmo Visual DB è di minimizzare la somma delle differenze tra ogni cella del dataset e suoi primi vicini, tramite permutazioni ottimali tra righe e colonne.
Se definiamo il dataset sorgente come una matrice, allora possiamo affermare che questa matrice appartiene ad un universo di stati di tutte le matrici generate permutando le sue colonne e le sue righe in tutti i modi possibili. Possiamo anche dire che tutte le matrici di tale universo sono equivalenti al dataset sorgente dal punto di vista della machine learning .
L’algoritmo Visual DB si basa sul presupposto che esista tra tutte queste matrici una “matrice ottimale”.
La matrice ottimale sarà quella matrice in cui la somma del quadrato della somma delle differenze tra ogni cella e le sue celle più prossime è la minore (considerando il dataset come una topologia toroidale).
L’algoritmo di Visual DB opera una esplorazione bottom-up, per cui ad ogni iterazione esegue delle trasformazioni sul dataset sorgente al fine di minimizzare la funzione di costo assegnata.
Esempi
Dataset sorgente→Matrice Ottima